We use Semaphore for automated testing. Just push changes and the tests are automatically run. Great. But there is a caveat as the test suite grows. Semaphore kills processes that run longer than an hour. At this point we integrated parallel_tests to reduce runtime. The result is great, overall runtime decreased to about one third.
Setting up parallel tests
Preparing database.yml can’t be done statically as the database name is randomly generated for each run. I wrote a rake task which adds the TEST_ENV_NUMBER variable to the database name:
namespace :testing do
task :prepare_db_config do |_t, _args|
if Rails.env.test?
db_config = YAML.load_file('config/database.yml')
db_config['test']['database'] += "<%= ENV['TEST_ENV_NUMBER'] %>" unless db_config['test']['database'].ends_with?("<%= ENV['TEST_ENV_NUMBER'] %>")
File.open('config/database.yml', 'w') { |f| f.write db_config.to_yaml }
end
end
The test environment is prepared by adding the following two lines at the end of the setup thread:
unset SPEC_OPTS # optionally if you want to use Insights with parallel_tests
bundle exec rake testing:prepare_db_config
bundle exec rake parallel:drop parallel:create parallel:migrate
Because we have two threads (i. e. separate machines that can do stuff simultaneously), we pass each thread a different regexp to tell it which tests to run:
SPEC_OPTS="--format progress --format json --out rspec_report.json" bundle exec rspec spec/features/
bundle exec rake parallel:spec[spec/models/]
As you can see, feature tests are not run with parallel. We often observed test failures due to lost or closed server connections and couldn’t fix it in considerable time. If you have a solution, I’d appreciate your comment.
The second thread gets the complementary regexp (and also checks whether everyone behaved by running rubocop):
bundle exec rake rubocop
bundle exec rake parallel:spec[^\(?\!spec/features\|spec/models\)]
If you are not sure whether you missed tests with your regexps, run your tests once with RSpec and then once with parallel_tests for each regexp. If the numbers of the latter add up to the number of tests run by RSpec you know you are right.
Use Insights with parallel tests
Semaphore recently launched a nice feature, Insights, which collects runtime data for tests. For RSpec it automatically injects the required parameters to generate the report. Unfortunately this does not work for the parallel command which runs most of our tests. But after some trial and error I found out how to set it up.
1. Generate JSON reports with parallel
Parallel can forward parameters to each RSpec process. But there is a problem, logging is not properly synced. If all processes write to the same file, the result is not JSON but a mess. So the idea is to use the TEST_ENV_NUMBER variable in the report file name for each process. I couldn’t figure out, how to specify that within the .rspec_parallel file (and doubt that it can be done because the parameters are forwarded within single quotes which prevents variable interpolation) but it worked by passing the required parameters directly to the rake task. Extend the parallel calls in your test threads this way:
bundle exec rake parallel:spec[spec/models/,"--format progress --format json --out parallel_report_\$TEST_ENV_NUMBER.json"]
The first format ensures you get the dots in STDOUT, the second tells RSpec to log the execution details in JSON format to some file (escaping the $ is crucial here).
2. Combining the reports
Insights expects all runtime data to be in a file called rspec_report.json in the root directory of your project. So we need another rake task to combine all logs:
namespace :testing do
task :combine_runtime_log, [:rspec_log_path, :parallel_logs_pattern] => [:environment] do |_t, args|
if Rails.env.test?
rspec_log_path = Pathname(args[:rspec_log_path])
log_hashes = Dir[args[:parallel_logs_pattern]].map { |path| JSON.parse(Pathname(path).read) }
log_hashes << JSON.parse(rspec_log_path.read) if rspec_log_path.exist?
result_hash = log_hashes.reduce { |a, e| a.tap { |m| m['examples'] += e['examples'] } }
rspec_log_path.write result_hash.to_json
end
end
end
The interesting data is found in the 'examples' key of the JSON, the other keys are the same in all files. The task above is called in both test thread as last command:
bundle exec rake testing:combine_runtime_log[rspec_report.json,parallel_report_*.json]
The task is written and called such that it also works, if there is no rspec_report.json which is important in cases all tests are run in parallel. It could also be called by the post thread and therefore would only have to be specified once. But then it gets executed even if one test thread fails which we decided against. Happy insighting!
Update (11/30/2015)
Shortly after I wrote this, Semaphore started to set SPEC_OPTS environment variable on the machines which overrides the format and logging parameters passed to parallel. So in order to get things running again, you need to unset this variable in your set-up thread and pass the specified options explicitly to the tests run with RSpec directly (I adjusted the code snippets above).
Recently I had a create form where one should be able to chose an associated model from a large set of possible values. It wouldn’t be too pleasant to have a drop down listing all these options. My idea was to render paginated radio buttons and a search field to limit the items available.
Submitting a query shouldn’t wipe out your previous inputs. So, both, create and search button, submit to the same action which then must decide by the button pressed what to do. As searching is a common concern I put this into a – surprise – Concern.
Form
Imagine a politics discussion board. You think it would be a nice feature if users could award prizes to politicians to honor their efforts. Maybe someone wants to award a politician for his achievements as a servant of a neoliberal lobby, e.g. the financial sector. So a user creates the „Disguised private investor bailout magician“ prize and needs to select the awardee. There are a lot of candidates, the German Bundestag alone currently already has 631 members. So here is how the form could look like:
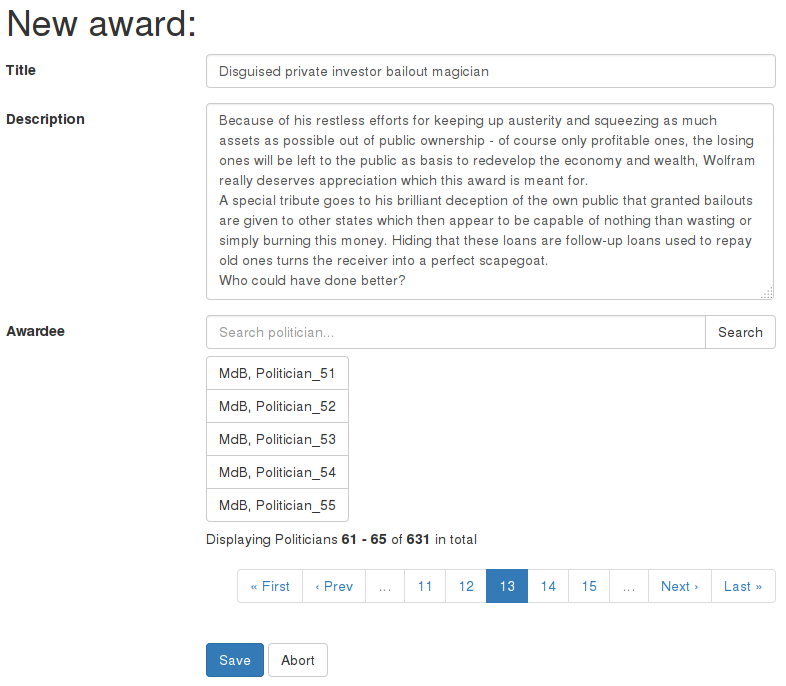
Form with entered award name and description
The labels and inputs for tile and description are regular form elements. Here is the code for the search field and the select options, pagination is done by kaminari:
<%= render layout: 'shared/paginated', locals: {collection: @politicians, entry_name: 'Politicians', params: {action: :new}} do %>
<div class="input-group">
<%= text_field_tag :query, params[:query], class: 'form-control', placeholder: 'Search politician...' %>
<div class="input-group-btn">
<%= button_tag type: 'submit', class: 'btn btn-default', name: :commit, value: :search_politicians do %>
Search
<% end %>
</div>
</div>
<div class="btn-group-vertical form-control-static" role="group" data-toggle="buttons">
<% @politicians.each do |politician| %>
<% active = politician.id.to_s == @award.awardee_id %>
<% classes = 'btn btn-default text-left-important' + (active ? ' active' : '') %>
<%= label_tag '', class: classes do %>
<%= f.radio_button 'awardee', politician.id %><%= "#{politician.last_name}, #{politician.first_name}" %>
<% end %>
<% end %>
</div>
<% end %>
The important parts are the text input named query and the button with value search_politicians to submit the query.
Controller
Here is what the controller actions for new and create look like – the magic happens in line 4 where the SearchAndRedirect concern is called:
class AwardsController < ApplicationController
include SearchAndRedirect
search_and_redirect commit: :search_politicians, redirects: {create: :new}, forwarded_params: [:award, :query]
def new
if params[:award]
@award = Award.new(params.require(:award).permit(:title, :description, :awardee_id))
else
@award = Award.new
end
@politicians = Politician.all.page(params[:page])
search = "%#{params[:query]}%"
@politicians = @politicians.where("first_name LIKE ? OR last_name LIKE ?", search, search) if params[:query].present?
end
def create
@award = Award.new(params.require(:award).permit(:title, :description, :awardee_id))
if @award.save
redirect_to :award, notice: 'Award was created.'
else
@politicians = Politician.all.page(params[:page])
render 'new'
end
end
end
search_and_redirect is called with three parameters: :commit, :redirects and :forwarded_params.
The :commit parameter tells the concern for which submit actions it should get active. So if a form is submitted with ’search_politicians‘ as commit value it will forward the specified parameters :award (to maintain previous inputs) and :query to the requested action.
In this case this rule applies if a form was submitted to the create action and will be redirected to new. As :redirects takes a hash, you can specify multiple redirects for the same forwarding rule.
Concern
Finally, here is the concern’s code:
module SearchAndRedirect
extend ActiveSupport::Concern
module ClassMethods
def search_and_redirect(options)
options.deep_stringify_keys!
commits = (options['commits'] || [options['commit']]).map(&:to_s)
before_filter only: options['redirects'].keys do
action = params[:action]
if commits.include?(params[:commit]) && options['redirects'].keys.include?(action)
forwarded_params = options['forwarded_params'].reduce({}) { |memo, param| memo.tap { |m| m[param] = params[param] } }
redirect_to({action: options['redirects'][action]}.merge(forwarded_params))
end
end
end
end
end
Now, we can search for Wolfram without having to rewrite the whole description again:
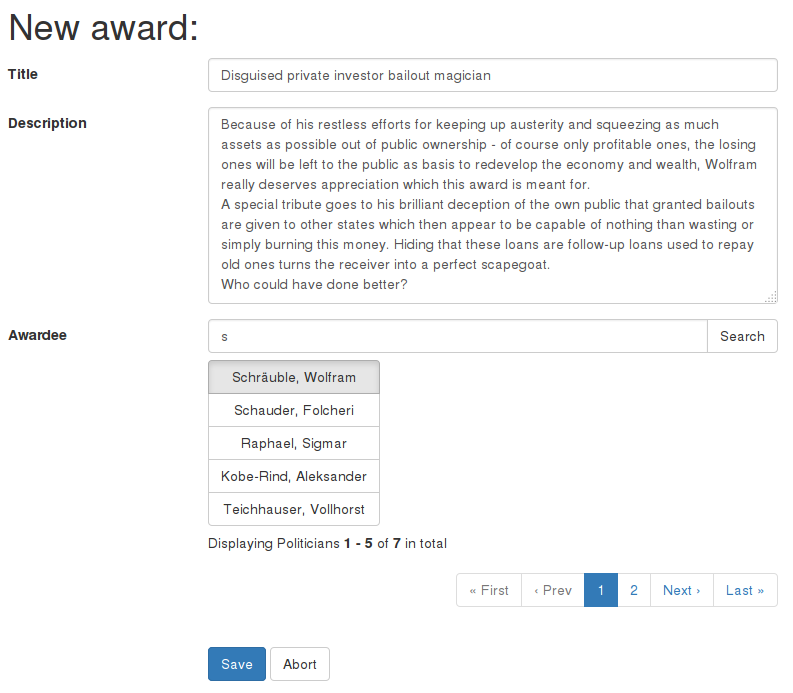
Form with preserved inputs after searching
Some model attributes in the project I’m working on have values which have to be mapped in the views. There are boolean values and enums which are not really meaningful as is.
Rails already provides built in support for mapping attribute and model names via Model.model_name.human and Model.human_attribute_name. Because they use the I18n API you can specify different translations for each locale.
Now, to map values, we could write helpers doing that. But to have the same flexibility, we would need to somehow use the I18n API, too. Instead of doing this in our custom application code, I thought it would be nice to have a similar mechanism for values on models and instances. Maybe something like human_attribute_value. So I wrote my first tiny gem: human_attribute_values.
Lookup meachanism
Following the conventions of the built in translation mechanisms, the translations are first looked up under activerecord.values.model_name.attribute_name.value, then values.attribute_name.value and if there is no translation found, the stringified value itself is returned.
I see the primary use case in translating booleans and enums, but it also supports numbers and, of course, strings. A bonus is the way STI models are handled: Rails steps up through the translations for ancestors until it finds a mapping.
The implementation is a small adjustment to the code of human_attribute_name. Because of this I’ll probably have to find a way to provide different implementations for different Rails versions someday.
I’ve been using powerline-shell for quite a while and like it a lot. I get aware of that every time I use a terminal which does not tell me which branch I’m on.
Some days ago I stumbled upon promptline.vim and as I’m also using vim-airline I gave it a try. Promptline.vim exports a shell script from the current airline settings.
After sourcing it into a shell you should immediately see the updated promptline (if there are random characters instead of fancy symbols, you need to install powerline symbols first):
:PromptlineSnapshot ~/.shell_prompt.sh airline
Automatically load the promptline when a shell is opened:
# load promptline if available
[ -f ~/.shell_prompt.sh ] && source ~/.shell_prompt.sh
Vim source
I use the light solarized theme created by Ethan Schoonover and invoked the export from vim looking like this:
Vim with airline status bar
Result
I tweaked the result a bit. Originally it only indicates whether, and if any, which changes have been made. I added coloring for the git slice, red for pending changes (both staged and unstaged):
- +3 indicates three files with unstaged chanegs
- •2 tells about two files with staged changes
- … indicates that there are untracked files
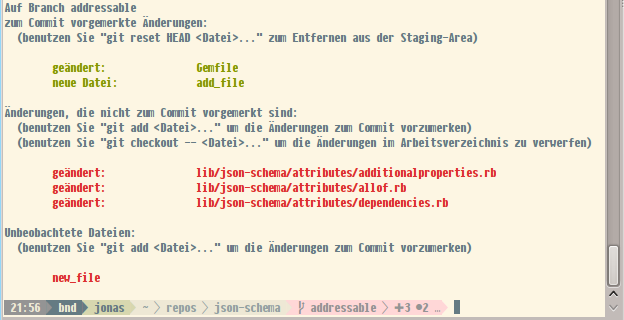
Bash with customized promptline
In a clean working directory or if there are only untracked files, the slice is green:

Promptline for a directory with untracked files/no changes
Customization
My .shell_prompt.sh (download) looks like this now:
#
# This shell prompt config file was created by promptline.vim
#
function __promptline_last_exit_code {
[[ $last_exit_code -gt 0 ]] || return 1;
printf "%s" "$last_exit_code"
}
function __promptline_ps1 {
local slice_prefix slice_empty_prefix slice_joiner slice_suffix is_prompt_empty=1
# section "aa" header
slice_prefix="${aa_bg}${sep}${aa_fg}${aa_bg}${space}" slice_suffix="$space${aa_sep_fg}" slice_joiner="${aa_fg}${aa_bg}${alt_sep}${space}" slice_empty_prefix="${aa_fg}${aa_bg}${space}"
[ $is_prompt_empty -eq 1 ] && slice_prefix="$slice_empty_prefix"
# section "a" slices
__promptline_wrapper "$(if [[ -n ${ZSH_VERSION-} ]]; then print %m; elif [[ -n ${FISH_VERSION-} ]]; then hostname -s; else printf "%s" \\A; fi )" "$slice_prefix" "$slice_suffix" && { slice_prefix="$slice_joiner"; is_prompt_empty=0; }
# section "a" header
slice_prefix="${a_bg}${sep}${a_fg}${a_bg}${space}" slice_suffix="$space${a_sep_fg}" slice_joiner="${a_fg}${a_bg}${alt_sep}${space}" slice_empty_prefix="${a_fg}${a_bg}${space}"
[ $is_prompt_empty -eq 1 ] && slice_prefix="$slice_empty_prefix"
# section "a" slices
__promptline_wrapper "$(if [[ -n ${ZSH_VERSION-} ]]; then print %m; elif [[ -n ${FISH_VERSION-} ]]; then hostname -s; else printf "%s" \\h; fi )" "$slice_prefix" "$slice_suffix" && { slice_prefix="$slice_joiner"; is_prompt_empty=0; }
# section "b" header
slice_prefix="${b_bg}${sep}${b_fg}${b_bg}${space}" slice_suffix="$space${b_sep_fg}" slice_joiner="${b_fg}${b_bg}${alt_sep}${space}" slice_empty_prefix="${b_fg}${b_bg}${space}"
[ $is_prompt_empty -eq 1 ] && slice_prefix="$slice_empty_prefix"
# section "b" slices
__promptline_wrapper "$USER" "$slice_prefix" "$slice_suffix" && { slice_prefix="$slice_joiner"; is_prompt_empty=0; }
# section "c" header
slice_prefix="${c_bg}${sep}${c_fg}${c_bg}${space}" slice_suffix="$space${c_sep_fg}" slice_joiner="${c_fg}${c_bg}${alt_sep}${space}" slice_empty_prefix="${c_fg}${c_bg}${space}"
[ $is_prompt_empty -eq 1 ] && slice_prefix="$slice_empty_prefix"
# section "c" slices
__promptline_wrapper "$(__promptline_cwd)" "$slice_prefix" "$slice_suffix" && { slice_prefix="$slice_joiner"; is_prompt_empty=0; }
# this will prepare the variables for __promptline_git_status and adjust the bg coloring for section "y"
__determine_git_colors
# section "y" header
slice_prefix="${y_bg}${sep}${y_fg}${y_bg}${space}" slice_suffix="$space${y_sep_fg}" slice_joiner="${y_fg}${y_bg}${alt_sep}${space}" slice_empty_prefix="${y_fg}${y_bg}${space}"
[ $is_prompt_empty -eq 1 ] && slice_prefix="$slice_empty_prefix"
# section "y" slices
__promptline_wrapper "$(__promptline_vcs_branch)" "$slice_prefix" "$slice_suffix" && { slice_prefix="$slice_joiner"; is_prompt_empty=0; }
__promptline_wrapper "$(__promptline_git_status)" "$slice_prefix" "$slice_suffix" && { slice_prefix="$slice_joiner"; is_prompt_empty=0; }
# section "warn" header
slice_prefix="${warn_bg}${sep}${warn_fg}${warn_bg}${space}" slice_suffix="$space${warn_sep_fg}" slice_joiner="${warn_fg}${warn_bg}${alt_sep}${space}" slice_empty_prefix="${warn_fg}${warn_bg}${space}"
[ $is_prompt_empty -eq 1 ] && slice_prefix="$slice_empty_prefix"
# section "warn" slices
__promptline_wrapper "$(__promptline_last_exit_code)" "$slice_prefix" "$slice_suffix" && { slice_prefix="$slice_joiner"; is_prompt_empty=0; }
# close sections
printf "%s" "${reset_bg}${sep}$reset$space"
}
function __promptline_vcs_branch {
local branch
local branch_symbol=" "
# git
if hash git 2>/dev/null; then
if branch=$( { git symbolic-ref --quiet HEAD || git rev-parse --short HEAD; } 2>/dev/null ); then
branch=${branch##*/}
printf "%s" "${branch_symbol}${branch:-unknown}"
return
fi
fi
return 1
}
function __determine_git_colors {
[[ $(git rev-parse --is-inside-work-tree 2>/dev/null) == true ]] || return 1
__promptline_git_unmerged_count=0 __promptline_git_modified_count=0 __promptline_git_has_untracked_files=0 __promptline_git_added_count=0 __promptline_git_is_clean=""
set -- $(git rev-list --left-right --count @{upstream}...HEAD 2>/dev/null)
__promptline_git_behind_count=$1
__promptline_git_ahead_count=$2
# Added (A), Copied (C), Deleted (D), Modified (M), Renamed (R), changed (T), Unmerged (U), Unknown (X), Broken (B)
while read line; do
case "$line" in
M*) __promptline_git_modified_count=$(( $__promptline_git_modified_count + 1 )) ;;
U*) __promptline_git_unmerged_count=$(( $__promptline_git_unmerged_count + 1 )) ;;
esac
done < <(git diff --name-status)
while read line; do
case "$line" in
*) __promptline_git_added_count=$(( $__promptline_git_added_count + 1 )) ;;
esac
done < <(git diff --name-status --cached)
if [ -n "$(git ls-files --others --exclude-standard)" ]; then
__promptline_git_has_untracked_files=1
fi
if [ $(( __promptline_git_unmerged_count + __promptline_git_modified_count + __promptline_git_has_untracked_files + __promptline_git_added_count )) -eq 0 ]; then
__promptline_git_is_clean=1
fi
y_fg="${wrap}38;5;246${end_wrap}"
# set green background for the branch info if there are no changes or only untracked files
if [[ $((__promptline_git_is_clean + __promptline_git_has_untracked_files)) -gt 0 ]]; then
y_bg="${wrap}48;5;194${end_wrap}"
y_sep_fg="${wrap}38;5;194${end_wrap}"
fi
# set red background for the branch info if there are unstaged or staged (but not yet committed) changes
if [[ $((__promptline_git_modified_count + __promptline_git_added_count)) -gt 0 ]]; then
y_bg="${wrap}48;5;224${end_wrap}"
y_sep_fg="${wrap}38;5;224${end_wrap}"
#y_bg="${wrap}48;5;217${end_wrap}"
#y_sep_fg="${wrap}38;5;217${end_wrap}"
fi
}
function __promptline_git_status {
[[ $(git rev-parse --is-inside-work-tree 2>/dev/null) == true ]] || return 1
local added_symbol="●"
local unmerged_symbol="✖"
local modified_symbol="✚"
local clean_symbol="✔"
local has_untracked_files_symbol="…"
local ahead_symbol="↑"
local behind_symbol="↓"
local leading_whitespace=""
[[ $__promptline_git_ahead_count -gt 0 ]] && { printf "%s" "$leading_whitespace$ahead_symbol$__promptline_git_ahead_count"; leading_whitespace=" "; }
[[ $__promptline_git_behind_count -gt 0 ]] && { printf "%s" "$leading_whitespace$behind_symbol$__promptline_git_behind_count"; leading_whitespace=" "; }
[[ $__promptline_git_modified_count -gt 0 ]] && { printf "%s" "$leading_whitespace$modified_symbol$__promptline_git_modified_count"; leading_whitespace=" "; }
[[ $__promptline_git_unmerged_count -gt 0 ]] && { printf "%s" "$leading_whitespace$unmerged_symbol$__promptline_git_unmerged_count"; leading_whitespace=" "; }
[[ $__promptline_git_added_count -gt 0 ]] && { printf "%s" "$leading_whitespace$added_symbol$__promptline_git_added_count"; leading_whitespace=" "; }
[[ $__promptline_git_has_untracked_files -gt 0 ]] && { printf "%s" "$leading_whitespace$has_untracked_files_symbol"; leading_whitespace=" "; }
[[ $__promptline_git_is_clean -gt 0 ]] && { printf "%s" "$leading_whitespace$clean_symbol"; leading_whitespace=" "; }
}
function __promptline_cwd {
local dir_limit="3"
local truncation="⋯"
local first_char
local part_count=0
local formatted_cwd=""
local dir_sep=" "
local tilde="~"
local cwd="${PWD/#$HOME/$tilde}"
# get first char of the path, i.e. tilde or slash
[[ -n ${ZSH_VERSION-} ]] && first_char=$cwd[1,1] || first_char=${cwd::1}
# remove leading tilde
cwd="${cwd#\~}"
while [[ "$cwd" == */* && "$cwd" != "/" ]]; do
# pop off last part of cwd
local part="${cwd##*/}"
cwd="${cwd%/*}"
formatted_cwd="$dir_sep$part$formatted_cwd"
part_count=$((part_count+1))
[[ $part_count -eq $dir_limit ]] && first_char="$truncation" && break
done
printf "%s" "$first_char$formatted_cwd"
}
function __promptline_left_prompt {
local slice_prefix slice_empty_prefix slice_joiner slice_suffix is_prompt_empty=1
# section "a" header
slice_prefix="${a_bg}${sep}${a_fg}${a_bg}${space}" slice_suffix="$space${a_sep_fg}" slice_joiner="${a_fg}${a_bg}${alt_sep}${space}" slice_empty_prefix="${a_fg}${a_bg}${space}"
[ $is_prompt_empty -eq 1 ] && slice_prefix="$slice_empty_prefix"
# section "a" slices
__promptline_wrapper "$(if [[ -n ${ZSH_VERSION-} ]]; then print %m; elif [[ -n ${FISH_VERSION-} ]]; then hostname -s; else printf "%s" \\h; fi )" "$slice_prefix" "$slice_suffix" && { slice_prefix="$slice_joiner"; is_prompt_empty=0; }
# section "b" header
slice_prefix="${b_bg}${sep}${b_fg}${b_bg}${space}" slice_suffix="$space${b_sep_fg}" slice_joiner="${b_fg}${b_bg}${alt_sep}${space}" slice_empty_prefix="${b_fg}${b_bg}${space}"
[ $is_prompt_empty -eq 1 ] && slice_prefix="$slice_empty_prefix"
# section "b" slices
__promptline_wrapper "$USER" "$slice_prefix" "$slice_suffix" && { slice_prefix="$slice_joiner"; is_prompt_empty=0; }
# section "c" header
slice_prefix="${c_bg}${sep}${c_fg}${c_bg}${space}" slice_suffix="$space${c_sep_fg}" slice_joiner="${c_fg}${c_bg}${alt_sep}${space}" slice_empty_prefix="${c_fg}${c_bg}${space}"
[ $is_prompt_empty -eq 1 ] && slice_prefix="$slice_empty_prefix"
# section "c" slices
__promptline_wrapper "$(__promptline_cwd)" "$slice_prefix" "$slice_suffix" && { slice_prefix="$slice_joiner"; is_prompt_empty=0; }
# close sections
printf "%s" "${reset_bg}${sep}$reset$space"
}
function __promptline_wrapper {
# wrap the text in $1 with $2 and $3, only if $1 is not empty
# $2 and $3 typically contain non-content-text, like color escape codes and separators
[[ -n "$1" ]] || return 1
printf "%s" "${2}${1}${3}"
}
function __promptline_right_prompt {
local slice_prefix slice_empty_prefix slice_joiner slice_suffix
# section "warn" header
slice_prefix="${warn_sep_fg}${rsep}${warn_fg}${warn_bg}${space}" slice_suffix="$space${warn_sep_fg}" slice_joiner="${warn_fg}${warn_bg}${alt_rsep}${space}" slice_empty_prefix=""
# section "warn" slices
__promptline_wrapper "$(__promptline_last_exit_code)" "$slice_prefix" "$slice_suffix" && { slice_prefix="$slice_joiner"; }
# section "y" header
slice_prefix="${y_sep_fg}${rsep}${y_fg}${y_bg}${space}" slice_suffix="$space${y_sep_fg}" slice_joiner="${y_fg}${y_bg}${alt_rsep}${space}" slice_empty_prefix=""
# section "y" slices
__promptline_wrapper "$(__promptline_vcs_branch)" "$slice_prefix" "$slice_suffix" && { slice_prefix="$slice_joiner"; }
# close sections
printf "%s" "$reset"
}
function __promptline {
local last_exit_code="${PROMPTLINE_LAST_EXIT_CODE:-$?}"
local esc=$'�[' end_esc=m
if [[ -n ${ZSH_VERSION-} ]]; then
local noprint='%{' end_noprint='%}'
elif [[ -n ${FISH_VERSION-} ]]; then
local noprint='' end_noprint=''
else
local noprint='\[' end_noprint='\]'
fi
local wrap="$noprint$esc" end_wrap="$end_esc$end_noprint"
local space=" "
local sep=""
local rsep=""
local alt_sep=""
local alt_rsep=""
local reset="${wrap}0${end_wrap}"
local reset_bg="${wrap}49${end_wrap}"
local aa_fg="${wrap}38;5;7${end_wrap}"
local aa_bg="${wrap}48;5;246${end_wrap}"
local aa_sep_fg="${wrap}38;5;246${end_wrap}"
local a_fg="${wrap}38;5;7${end_wrap}"
local a_bg="${wrap}48;5;11${end_wrap}"
local a_sep_fg="${wrap}38;5;11${end_wrap}"
local b_fg="${wrap}38;5;11${end_wrap}"
# set red background for root
if [ $UID == 0 ]; then
local b_bg="${wrap}48;5;210${end_wrap}"
local b_sep_fg="${wrap}38;5;210${end_wrap}"
# set light green background for anyone else
else
local b_bg="${wrap}48;5;187${end_wrap}"
local b_sep_fg="${wrap}38;5;187${end_wrap}"
fi
local c_fg="${wrap}38;5;14${end_wrap}"
local c_bg="${wrap}48;5;7${end_wrap}"
local c_sep_fg="${wrap}38;5;7${end_wrap}"
local warn_fg="${wrap}38;5;15${end_wrap}"
local warn_bg="${wrap}48;5;9${end_wrap}"
local warn_sep_fg="${wrap}38;5;9${end_wrap}"
local y_fg="${wrap}38;5;14${end_wrap}"
local y_bg="${wrap}48;5;14${end_wrap}"
local y_sep_fg="${wrap}38;5;14${end_wrap}"
if [[ -n ${ZSH_VERSION-} ]]; then
PROMPT="$(__promptline_left_prompt)"
RPROMPT="$(__promptline_right_prompt)"
elif [[ -n ${FISH_VERSION-} ]]; then
if [[ -n "$1" ]]; then
[[ "$1" = "left" ]] && __promptline_left_prompt || __promptline_right_prompt
else
__promptline_ps1
fi
else
PS1="$(__promptline_ps1)"
fi
}
if [[ -n ${ZSH_VERSION-} ]]; then
if [[ ! ${precmd_functions[(r)__promptline]} == __promptline ]]; then
precmd_functions+=(__promptline)
fi
elif [[ -n ${FISH_VERSION-} ]]; then
__promptline "$1"
else
if [[ ! "$PROMPT_COMMAND" == *__promptline* ]]; then
PROMPT_COMMAND='__promptline;'$'\n'"$PROMPT_COMMAND"
fi
fi
Changes:
- line 14-16: Add slice with current time (only works in bash as is)
- line 71-137: Add functions to determine git status
- line 39: Determine git details and coloring for ‚y‘-section before rendering starts
- line 45: Call git status rendering
- line 234-259: Changed some colors, added ‚aa‘-colors, user name background depends on being root or not
I took the logic for the git status slice from promptline.vim and adjusted it so that the coloring for the slice is determined before its rendering starts.
Colors can be adjusted by changing the third value of the tuples, a nice cheat-sheet can be found here.
November 13th, 2014 in
Programming | tags:
Bash,
Git,
Shell |
4 Comments
Imagine you want to provide some content but at the same time hide its true origin. Sounds ridiculous? Well, there may be good reasons to do so:
- hide the original server from the net for security reasons
- circumvent or help to circumvent location based censorship
- make content of some unsuitable CMS available to authorized users only (estimated effort to switch CMS is about ‚one hundred before thousand‘ – the largest number known to mankind)
From the technical perspective the actual reason is not so important – let’s get on with the details:
Setting up the gateway
If you want to use the path /proxy/ as entry point for your gateway to www.example.com then you need to enable mod_proxy and mod_proxy_http and define PassProxy and PassProxyReverse directives for that:
<Location /proxy/>
ProxyPass http://www.example.com/
ProxyPassReverse http://www.example.com/
</Location>
An SSL remote additionally needs mod_proxy_connect and the following directives in the virtual host:
# required
SSLProxyEngine On
# recommended
SSLProxyCheckPeerCN On
SSLProxyCheckPeerExpire On
Rewrite links in the returned page
Links and referenced style sheets in the retrieved page will point to the proxied URL. Using mod_proxy_html Apache2 can rewrite them to also go through the proxy. For me the Perl implementation worked better (needs mod_perl):
PerlInputFilterHandler Apache2::ModProxyPerlHtml
PerlOutputFilterHandler Apache2::ModProxyPerlHtml
<Location /proxy/>
# inflate and deflate enables processing of compressed pages
SetOutputFilter INFLATE;proxy-html;DEFLATE
# multiple mappings and use of regular expressions possible
PerlAddVar ProxyHTMLURLMap "http://www.example.com/ /proxy/"
</Location>
The complete gateway configuration:
SSLProxyEngine On
SSLProxyCheckPeerCN On
SSLProxyCheckPeerExpire On
PerlInputFilterHandler Apache2::ModProxyPerlHtml
PerlOutputFilterHandler Apache2::ModProxyPerlHtml
<Location /proxy/>
ProxyPass http://www.example.com/
ProxyPassReverse http://www.example.com/
SetOutputFilter INFLATE;proxy-html;DEFLATE
PerlAddVar ProxyHTMLURLMap "http://www.example.com/ /proxy/"
</Location>
Further notes
If the proxied site relies on cookies, then you need to configure ProxyPassReverseCookieDomain and ProxyPassReverseCookiePath.
ProxyPassReverse will only rewrite Location, Content-Location and URI headers. If you need any other headers rewritten, you must put additional measures into place.
Docs for the used proxy modules: mod_proxy, mod_proxy_http, mod_proxy_connect
Die letzte Mail, die mir mitteilte, meine neue KabelBW-Rechnung sei nun online abrufbar, verwies mich auf https://app.unitymedia.de/kundencenter/sitzung/anmelden.
Mein Login-Versuch wurde mit „Logindaten falsch“ quittiert. Was solls, Passwörter vergisst man schon mal, also Rücksetzfunktion benutzen und auf ein neues. Jetzt mit ganz sicher den richtigen Zugangsdaten – sollte man meinen. Wieder dieselbe Fehlermeldung.
Ende vom Lied: https://app.kabelbw.de/kundencenter/sitzung/anmelden sieht zwar gleich aus, ist aber nicht dasselbe. Dort funktionieren dann auch die über die unitymedia-Domain geänderten Zugangsdaten. Klingt komisch, ist aber so.
Yesterday I wanted to continue ongoing work I started on a different machine. But the code was not clean when I left, so I didn’t commit.
To prevent a dirty commit I temporarily committed my work on the remote machine, then pulled that commit directly from there and afterwards discarded the temporary commit on the other machine. No bad commit left:
$ git add .
$ git commit -m "Temporary commit"
$ git checkout -b my_branch
$ git pull ssh://user@remote.host:port/path/to/repository my_branch
$ git reset 'HEAD^'
A final git reset 'HEAD^' on the remote makes the commit to have never happened.
April 11th, 2014 in
Programming |
No Comments
When I was looking for a gem to parse PDF text, pdf-reader turned out to be a good choice. Unfortunately there is only a simple text output for pages. To process content using text positions, a little customization is required to retrieve them.
Customized subclasses (1)
The Page class provides a #walk method which takes visitors that get called with the rendering instructions for the page content. To get access to the text runs on a page, a subclass of PageTextReceiver can be used, which only adds readers for the @characters and @mediabox attributes:
class CustomPageTextReceiver < PDF::Reader::PageTextReceiver
attr_reader :characters, :mediabox
end
With these two values, PageLayout can be instantiated. It merges found characters into word groups (runs). To retrieve these runs afterwards, we also need a slighty chattier subclass:
class CustomPageLayout < PDF::Reader::PageLayout
attr_reader :runs
end
Custom subclasses (2)
Using these two subclasses we could now retrieve the text from PDFs together with its coordinates. But I observed two drawbacks with the original implementations.
First, I had files for which the outputted runs contained duplicates which seems to stem from text with shadowing. This can be handled by rejecting duplicates while PageLayout processes them:
class CustomPageLayout < PDF::Reader::PageLayout
attr_reader :runs
def group_chars_into_runs(chars)
# filter out duplicate chars before going on with regular logic,
# seems to happen with shadowed text
chars.uniq! {|val| {x: val.x, y: val.y, text: val.text}}
super
end
end
Second, in some cases pdf-reader missed spaces in the parsed text, which I think may happen because originally it calculates spaces itself and PageTextReceiver discards spaces found in the PDF stream. I found it to be more reliable to keep spaces and strip extra spaces during further processing:
class PageTextReceiverKeepSpaces < PDF::Reader::PageTextReceiver
# We must expose the characters and mediabox attributes to instantiate PageLayout
attr_reader :characters, :mediabox
private
def internal_show_text(string)
if @state.current_font.nil?
raise PDF::Reader::MalformedPDFError, "current font is invalid"
end
glyphs = @state.current_font.unpack(string)
glyphs.each_with_index do |glyph_code, index|
# paint the current glyph
newx, newy = @state.trm_transform(0,0)
utf8_chars = @state.current_font.to_utf8(glyph_code)
# apply to glyph displacment for the current glyph so the next
# glyph will appear in the correct position
glyph_width = @state.current_font.glyph_width(glyph_code) / 1000.0
th = 1
scaled_glyph_width = glyph_width * @state.font_size * th
# modification to original pdf-reader code which accidentally removes spaces in some cases
# unless utf8_chars == SPACE
@characters << PDF::Reader::TextRun.new(newx, newy, scaled_glyph_width, @state.font_size, utf8_chars)
# end
@state.process_glyph_displacement(glyph_width, 0, utf8_chars == SPACE)
end
end
end
It is the original code except for the two highlighted lines which are commented out to keep also spaces.
Further processing
Based on the customized PageTextReceiver and PageLayout I wrote a basic processor which takes the runs of each page and brings them in a structured form for further processing.
The processor class can be found in the following script, invoke with ./script.rb /path/to/some.pdf when the pdf-reader gem is installed:
#! /usr/bin/ruby
require 'pdf-reader'
class CustomPageLayout < PDF::Reader::PageLayout
attr_reader :runs
# we need to filter duplicate characters which seem to be caused by shadowing
def group_chars_into_runs(chars)
# filter out duplicate chars before going on with regular logic,
# seems to happen with shadowed text
chars.uniq! {|val| {x: val.x, y: val.y, text: val.text}}
super
end
end
class PageTextReceiverKeepSpaces < PDF::Reader::PageTextReceiver
# We must expose the characters and mediabox attributes to instantiate PageLayout
attr_reader :characters, :mediabox
private
def internal_show_text(string)
if @state.current_font.nil?
raise PDF::Reader::MalformedPDFError, "current font is invalid"
end
glyphs = @state.current_font.unpack(string)
glyphs.each_with_index do |glyph_code, index|
# paint the current glyph
newx, newy = @state.trm_transform(0,0)
utf8_chars = @state.current_font.to_utf8(glyph_code)
# apply to glyph displacment for the current glyph so the next
# glyph will appear in the correct position
glyph_width = @state.current_font.glyph_width(glyph_code) / 1000.0
th = 1
scaled_glyph_width = glyph_width * @state.font_size * th
# modification to the original pdf-reader code which otherwise accidentally removes spaces in some cases
# unless utf8_chars == SPACE
@characters << PDF::Reader::TextRun.new(newx, newy, scaled_glyph_width, @state.font_size, utf8_chars)
# end
@state.process_glyph_displacement(glyph_width, 0, utf8_chars == SPACE)
end
end
end
class PDFTextProcessor
MAX_KERNING_DISTANCE = 10 # experimental value
# pages may specify which pages to actually parse (zero based)
# [0, 3] will process only the first and fourth page if present
def self.process(pdf_io, pages = nil)
pdf_io.rewind
reader = PDF::Reader.new(pdf_io)
fail 'Could not find any pages in the given document' if reader.pages.empty?
processed_pages = []
text_receiver = PageTextReceiverKeepSpaces.new
requested_pages = pages ? reader.pages.values_at(*pages) : reader.pages
requested_pages.each do |page|
unless page.nil?
page.walk(text_receiver)
runs = CustomPageLayout.new(text_receiver.characters, text_receiver.mediabox).runs
# sort text runs from top left to bottom right
# read as: if both runs are on the same line first take the leftmost, else the uppermost - (0,0) is bottom left
runs.sort! {|r1, r2| r2.y == r1.y ? r1.x <=> r2.x : r2.y <=> r1.y}
# group runs by lines and merge those that are close to each other
lines_hash = {}
runs.each do |run|
lines_hash[run.y] ||= []
# runs that are very close to each other are considered to belong to the same text "block"
if lines_hash[run.y].empty? || (lines_hash[run.y].last.last.endx + MAX_KERNING_DISTANCE < run.x)
lines_hash[run.y] << [run]
else
lines_hash[run.y].last << run
end
end
lines = []
lines_hash.each do |y, run_groups|
lines << {y: y, text_groups: []}
run_groups.each do |run_group|
group_text = run_group.map { |run| run.text }.join('').strip
lines.last[:text_groups] << ({
x: run_group.first.x,
width: run_group.last.endx - run_group.first.x,
text: group_text,
}) unless group_text.empty?
end
end
# consistent indexing with pages param and reader.pages selection
processed_pages << {page: page.number, lines: lines}
end
end
processed_pages
end
end
if File.exists?(ARGV[0])
file = File.open(ARGV[0])
pages = PDFTextProcessor.process(file)
puts pages
puts "Parsed #{pages.count} pages"
else
puts "Cannot open file '#{ARGV[0]}' (or no file given)"
end
The overall output is an array of hashes where each hash covers the text on a page. Each page hash has an array of lines in which each line is also represented by an hash. A line has an y-position and an array of text groups found in this line. Lines are sorted from top to bottom ([0,0] is on the bottom left) and text groups from left to right:
{
page: 1,
lines: [
{
y: 771.4006,
text_groups: [
{x: 60.7191, width: 164.6489200000004, text: "Some text on the left"},
{x: 414.8391, width: 119.76381600000008, text: "Some text on the right"}
]
},
{
y: 750.7606,
text_groups: [{x: 60.7191, width: 88.51979999999986, text: "More text"}]
}
]
}
Running a server for a long time certainly, if not probably means migration some day. Usually, at least for private servers, this is fairly simple. Config files and even databases can be moved without an export/import cycle. But when it comes to users and access rights, there may be dragons.
My dragon lurked at the interplay between Postfix and the SASL authentication daemon which broke the authentication of mail clients. When a client tried to send a mail, the mail log said:
SASL LOGIN authentication failed: generic failure
Browsing for a solution I came across tutorials describing the setup of a mail server from scratch. I started to check whether I accidentally broke a step and indeed, the postfix user could not access salsauthd’s socket. I fixed this with the following two commands:
chgrp sasl /var/spool/postfix/var/run/saslauthd
adduser postfix sasl
After restarting Postfix and saslauthd, everything worked fine again.
More fun with Postfix and SASL authentication
Because I ignored the problem for some time, I had a different problem first: The way how to configure SASL authentication changed (current setup is Debian Wheezy with Postfix 2.9). First Postfix told me, it could not even find an auth mechanism:
SASL PLAIN authentication failed: no mechanism available
This could be fixed by changing the config (/etc/postfix/sasl/smtpd.conf on my machine) from:
pwcheck_method: saslauthd
saslauthd_path: /var/run/saslauthd/mux
log_level: 3
mech_list: plain login
allow_plaintext: true
auxprop_plugin: mysql
sql_hostnames: 127.0.0.1
sql_user: db_user
sql_passwd: db_password
sql_database: db_name
sql_select: select password from mailbox where username = '%u'
to:
pwcheck_method: saslauthd
saslauthd_path: /var/run/saslauthd/mux
log_level: 3
mech_list: plain login
allow_plaintext: true
auxprop_plugin: sql
sql_engine: mysql
sql_hostnames: 127.0.0.1
sql_user: db_user
sql_passwd: db_password
sql_database: db_name
sql_select: select password from mailbox where username = '%u@%r'
Von meinem neuen Internetanbieter habe ich eine Fritzbox 6340 als Router bekommen. An und für sich ist das Gerät Ok, man kann nicht alles frei konfigurieren aber komplett kastriert ist das Menü auch nicht. Allerdings stellte sich dann heraus, dass gefühlt jeder dritte bis sechste Versuch eine WLAN-Verbindung aufzubauen mit der Meldung scheiterte, dass die Authentifizierung fehlgeschlagen sei. Nach einem Neustart des WLANs über den Taster am Router klappte es dann. Allerdings ist das keine Dauerlösung.
Da das Problem bei voller Signalstärke und auch direkt neben dem Router auftritt und auch so Sachen wie Kanalwechsel nichts gebracht haben, habe ich mich an den Support gewandt. Der hat mir vorgeschlagen, es mit einem kürzeren Passwort zu versuchen, weil das wohl mal in einem Fall geholfen hat – Vodoo oder fieser Firmwarefehler? – auf jeden Fall keine sinnvolle Alternative.
Im Log (erweiterte Menüansicht, „System“ -> „Ereignisse“) fand ich dann schließlich den Eintrag:
WLAN-Anmeldung ist gescheitert. Maximale Anzahl gleichzeitig nutzbarer WLAN-Geräte erreicht. #002.
Das kam mir komisch vor, denn Verbunden (bzw. authentifiziert) sind im (W)LAN höchstens 10 Geräte. Es scheint so, als ob die Fritzbox durch Verbindungsanfragen anderer Geräte blockiert wird. Die Geräteliste unter „WLAN“ -> „Funknetz“ war voll von Einträgen fremder Geräte, die sich natürlich nicht authentifizieren konnten. Ich würde eigentlich erwarten, dass das kein Problem darstellt, aber wenn man hier den WLAN-Zugang auf bekannte Geräte beschränkt und alle Einträge zu Fremdgeräten löscht, tritt das Problem nicht mehr auf.



